


Simplifying AI Deployment for Defense
A guide to navigating ATOs, classified data, hardware constraints, security testing, classified networks, and more


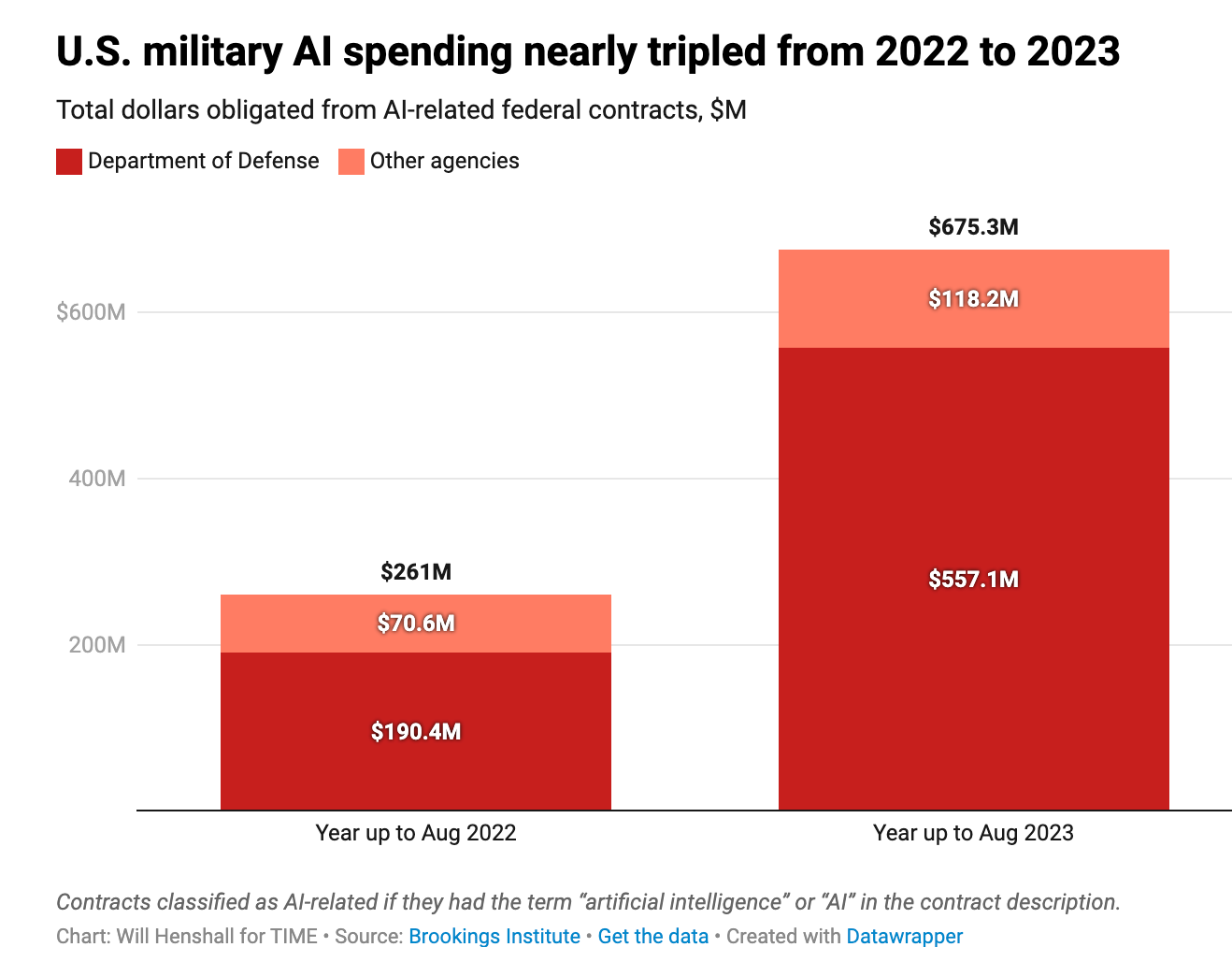
Much ink has been spilled on the potential for AI to revolutionize national security use cases.1 In September 2023, the CIA announced that it had developed its own version of ChatGPT, and in early June 2024, the US Air Force released NIPRGPT, an experimental project to leverage generative AI on the Non-classified Internet Protocol Router Network (NIPRNet), the Department of Defense’s (DoD) unclassified intranet service. Overall, U.S. military expenditure on AI surged nearly threefold from 2022 to 2023.
While the opportunities for startups to participate are immense, major challenges persist in deploying their leading-edge technology in the DoD and intelligence community (IC). Before selling AI to national security customers, developers of AI-enabled applications need to understand what is required to actually develop and deploy AI systems in the DoD and IC. To better understand the national security AI development and deployment process (and the challenges to consider), I asked my friend Max Dauber, who has real-world experience developing and deploying AI for the DoD and IC, to co-author this blog post with me. Together, we interviewed a number of our friends at other startups and defense primes, along with those inside the government to gather a rough consensus view of what it takes to develop and deploy AI for national security customers.
Develop
There are two pieces of the development process that need to be attended to in order to develop AI models for national security customers: 1) data and 2) security, testing, and evaluation.
Data
As the common refrain goes, machine learning (ML) models are only as good as the data they are trained on. Finding, cleaning, and getting permission to work with national security data can be a real challenge for those building AI models for national security customers. The DoD and IC are sitting on “Scrooge McDuck” levels of unique data – decades worth of design and operations manuals for hardware systems, war game results, geospatial intelligence, signals intelligence, human intelligence reports, cutting-edge scientific research, etc. Currently this data is siloed, unorganized, overclassified, and difficult to find. Much of this data has yet to even be digitized (although the DoD is undergoing a number of digitization efforts).
Even when data is digitized, much of it is not in a format that is easily ingested by AI models (ex: it is unstructured, unlabelled, etc.). Often, model developers need to employ open-source tools like Unstructured to transform unstructured data sources (ex: PDFs, PowerPoints, etc) into a form that is AI-ready. These transformations can include partitioning, cleaning, and chunking for a wide variety of text-based formats as well as extracting text from images or converting speech recordings into written transcripts. Additionally, many rely on data labeling vendors like Scale AI to label data so that it can be used to train ML models. Data labeling is such an important task that the DoD’s Chief Digital and AI Office (CDAO) recently released a data labeling service as part of its portfolio of AI infrastructure services (known as Alpha-1).

As an illustrative example: Project Maven, one of the DoD’s largest AI initiatives, spends about $100M each year on data acquisition, data curation, data labeling, and DevSecOps and has a team of 400 data labelers working eight-hour shifts year round, labeling geospatial intelligence (GEOINT) data (both classified and unclassified) from different sources.
Furthermore, a significant amount of relevant national security data is classified. In order to get access to this classified data, model developers need team members with security clearances to access this data on classified networks. There is an extremely limited talent pool of engineers (particularly ML engineers) with security clearances and recruiting those engineers can be a challenge.
Working with classified data is also difficult because models built on classified data need to be trained on classified networks like the Secret Internet Protocol Router Network (SIPRNet) and the Joint Worldwide Intelligence Communication System (JWICS). Classified networks are physically isolated from unclassified networks and are extremely GPU-constrained. Training ML models is highly GPU-intensive, so training in GPU-constrained networks can lead to serious challenges.
To get around the challenges of working with classified data, AI developers have several options: (1) synthetic data or (2) unclassified data.
First, some model developers may seek to use synthetic data (computer generated, unclassified data that is similar to classified data). However, using synthetic data can degrade model performance.
Other model developers may choose to orient their products around unclassified data. Over the past few decades, there has been an explosion in high quality open source data (ex: news articles, social media data, financial data, shipping data, etc), often referred to as open source intelligence (OSINT), that can have a tremendous impact on national security. For example, Vannevar Labs focuses on developing AI tools to analyze OSINT, sidestepping classified data entirely (analysts can still use Vannevar for classified workloads, but the data being analyzed is not classified). There are a broad set of options for collecting OSINT including buying from data providers, developing bespoke web scrapers, connecting to public record databases, and many others. The war in Ukraine in particular has shown the power of combining traditional intelligence sources with OSINT. However, model developers should use caution when training AI models on unclassified data, as there may be unknown edge cases or patterns in classified data that are not represented in unclassified data sets.
It’s important to ensure that the datasets used to train national security AI are sufficiently relevant and diverse. One startup CTO we spoke with pointed out that the DoD does not always have the data necessary to create powerful, relevant applications for current and future conflicts. Similarly, one former DoD official who supported Project Maven noted, “Acquiring sufficient data that is diverse enough to be useful is tough. We have a labeled dataset that is good for desert clear-sky, high-sun conditions, but if you take that AI model to a snowy landscape, the performance drops.” Further, drone and missile autonomy performance can be massively degraded in urban environments when compared to open fields and forests.
During the Global War on Terror, for instance, the DoD amassed a large set of Arabic language and Middle East-focused data.2 However, as the DoD shifted its focus to Great Power Competition with countries like China, the DoD found that it lacked large datasets focused on China and the Mandarin language in particular. As a result, AI product developers may need to curate their own datasets, as they cannot rely on the DoD to have the necessary data.
Similarly, AI model developers can gain a strategic advantage if they are able to get access to real combat data. For example, one computer vision startup we met had curated a relationship with Ukrainian military units in order to gain access to hundreds of hours of Ukrainian combat footage. This startup believes that this footage will enable them to develop better computer vision algorithms that can effectively detect key targets (for instance, tanks), even if they are damaged or camouflaged.
Once a model developer has identified its training data, ensuring the inference data is similarly high quality is critical for the effective deployment of AI applications, especially in classified networks. Training data is used to build and fine-tune the AI models, focusing on capturing a wide variety of scenarios the model may encounter. In contrast, inference data is what the model interacts with in real-time after deployment, used to make decisions or predictions. Many AI applications rely on access to specific real-time data sources, which may not be available in an air-gapped classified network. For instance, one startup we spoke with likes to pull in real time AIS data (Automatic Identification System) to enrich its AI application. However, once that startup deploys its application on classified networks, it is not guaranteed to have access to real time AIS data if no AIS data stream is available on classified networks.
Security, Testing, & Evaluation
Unsurprisingly, national security customers are extremely security-conscious when deploying any software onto sensitive networks. All AI applications deployed in national security networks will need to adhere to strict security standards. In general, national security customers are not comfortable using AI models that are hosted in non-government cloud infrastructure. So, AI models will likely need to be deployed either on-prem, on edge, or in government cloud infrastructure to ensure that sensitive data is not leaked outside of national security networks.
Additionally, model developers will need to ensure that their models are protected against common ML security risks like data poisoning, prompt injections, data leakage, adversarial example attacks, and others. Over the past few years, a number of startups such as HiddenLayer, Robust Intelligence, Lakera, Knostic AI, and Arthur AI have emerged to help model developers secure and red-team their AI models. Thus far, national security customers and regulatory bodies like NIST have not defined robust security standards for ML security in the same way they have for traditional software. So, AI application developers will need to work with end users and self-regulate to ensure that their models are secure enough for national security customers.
Finally, AI applications will need to undergo traditional software security testing, in addition to security testing focused on ML. The Authority to Operate (ATO) process requires software to be scanned for and hardened against common vulnerabilities, CVEs, and dependency attacks.
In addition to security testing, model developers also need to test and evaluate the performance and quality of their AI models. Like security testing, performance testing and evaluation best practices for national security use cases of AI remain poorly defined, particularly for large language models (LLMs).3 Testing is critical to ensure that models perform acceptably on inputs outside of their training dataset, especially when no classified or operational data was available to train on directly. According to model developers we spoke with, evaluation criteria for AI models are negotiated back and forth between developers and government customers. Even after deployment, ML models need to be continuously tested and monitored to ensure model quality does not degrade over time.
There are several ongoing initiatives to develop evaluation frameworks for AI models:
The CDAO (in partnership with Scale AI) is actively working on releasing an open-source evaluation framework for LLMs.
Each service is also separately working on their own evaluation frameworks (for instance, see the Navy’s GenAI guidance).
MIT Lincoln Lab, a DoD research lab run by MIT, is working to develop benchmarks for defense-related ML models.
In April 2024, NIST released a draft AI Risk Framework to help assess the risks present in ML models.
CDAO released its “Responsible AI Toolkit,” a toolkit to help model developers track and improve AI model performance based on ethical principles.
Several startups we spoke with are using CDAO’s Responsible AI Toolkit to evaluate their ML models for problems like model bias. Others have developed their own evaluation benchmarks. For example, one group we met using LLMs to automate administrative national security workflows developed a benchmark that evaluates an LLM’s ability to understand a data set of common DoD acronyms.
Finally, one of CDAO’s primary areas of interest for responsible AI is “explainability.” AI algorithms are often described as “black boxes”, as it can be difficult to understand how they make decisions. However, companies like HowSo and Fiddler AI are working to enhance AI explainability using techniques like complex SHAP value metrics and gradient-based explanations. Explainability techniques today are far from perfect (and not generally required yet), but model developers should consider incorporating explainability features where possible, especially for mission-critical or kinetic applications such as automated target recognition.
Deploy
There are four pieces of the model deployment process that need attention when deploying AI applications for national security customers: 1) integration, 2) certification and accreditation, 3) hardware constraints, and 4) classified networks.
Integration
When developing an AI application, it is crucial to understand the existing software systems (databases, ERP systems, etc.) a new application will need to integrate with. As outlined in a Defense Innovation Board (DIB) report (and as I’ve written about previously), the DoD has an “API problem.” In the commercial, non-government world, most modern software products have easy to use application programming interfaces (APIs) that enable data integration between different systems. However, much of the software used by the DoD lacks high quality APIs, making it difficult to integrate applications developed by different vendors and causing significant duplication of effort. One horror story relayed to us, for instance, involved DoD personnel manually re-entering thousands of lines of data from one service’s ERP into another service’s. Further, much of the national security community’s software is “homegrown” and tailored to very specific (and sometimes classified) workflows, making it difficult to replace. Much of this homegrown software is brittle, and written in legacy coding languages, so it is difficult to update, maintain, and integrate with. The status quo, as the DIB has emphasized, is unacceptable.
This lack of high-quality APIs may make it difficult for AI applications to extract and use data from other DoD applications. Similarly, AI applications may struggle to populate other DoD applications with new data or otherwise manipulate other applications. Many of the most exciting applications of AI in the commercial world involve AI models manipulating other applications (ex: AI agents that are able to buy plane tickets, book hotel rooms, patch software, etc). Deprived of APIs, the DoD may not be able to benefit from these breakthroughs, necessitating inefficient workarounds like “RPA-style” agents, which point and click on web applications like human users.
One way to ease integration with other applications is to consider the data standards used by end customers and their existing platforms. For instance, AI models that analyze drone telemetry data should be prepared to ingest this data in the MISB format, a National Geospatial Agency (NGA) data standard. Similarly, those deploying drones should ensure their telemetry data is in the MISB format for future AI applications.
These data integration challenges will differ across military services and organizations. For example, the US Air Force (USAF) and Space Force (USSF) have developed a cloud environment known as the “Unified Data Library” (UDL) which ingests data from different sensors and standardizes the data.4 Similarly, the Army uses a “data fabric” solution developed by Booz Allen Hamilton called “Rainmaker.” Those developing AI applications should understand the data platforms used by their end customers and prepare to integrate with those data formats.
Certification and Accreditation
In order to actually deploy an AI application to national security customers on DoD and IC networks like SIPRNet and JWICS, it is necessary to get the software certified and accredited. Software used by DoD and IC customers must be granted an “Authority to Operate” (ATO). The CEO of one AI startup we spoke with emphasized the importance of starting the ATO process as soon as possible, as the process can take months (and likely will take longer than expected).
To be granted an ATO, software must go through the ATO process, a process designed to minimize and manage software risk. During the ATO process, software is thoroughly tested, security vulnerabilities are identified and mitigated, and software dependencies are cataloged and upgraded.
In the meantime, while waiting to get an official ATO from an Authorizing Official (AO), the government can issue an Interim Authority to Test (IATT), which grants a company permission to test their system without live, classified data. For those building new AI applications for national security customers, getting an IATT can be a great way to get initial product feedback from end users before completing the arduous ATO process.
There are several new products that can speed up the ATO process. Second Front Systems’s product Gamewarden enables software providers to fast track the ATO process to quickly deploy on national security networks. Similarly, Palantir’s FedSTART product, part of Palantir’s broader “First Breakfast” initiative that aims to help startups access national security customers, enables startups to shortcut the ATO process by deploying software in Palantir’s environment, taking advantage of Palantir’s ATO and FedRAMP certification.
Notably, an ATO from one government agency does not transfer to another government agency. So, it is important to identify target customer agencies and begin the separate ATO processes as early as possible.
Hardware Constraints
When deploying AI to national security customers, it is essential to consider the hardware an AI application will have access to. For many national security use cases, AI models will need to run offline on edge devices with considerable size, weight, and power (SWaP) constraints. Computer vision models for drones to navigate in GPS- and communications-denied environments will need to run on-device with limited power budgets. Military applications will demand ML algorithms built for edge devices from drones and ATAK, to iPads strapped to airmen’s legs.5
Even when not deploying AI in comms-denied edge devices, some customers may not want to run AI models in the commercial cloud due to security concerns. Defense AI applications will need to be able to run on whatever hardware end users happen to have lying around. Even if an AI application developer is able to make use of cloud resources, many government cloud providers have a limited number of GPUs available for government workloads. Most (but not all) cloud providers are required to physically separate government compute hardware from non-government compute hardware. As a result of GPU constraints, many model developers choose to conduct all model training, which is particularly GPU intensive, on unclassified data in unclassified networks.6
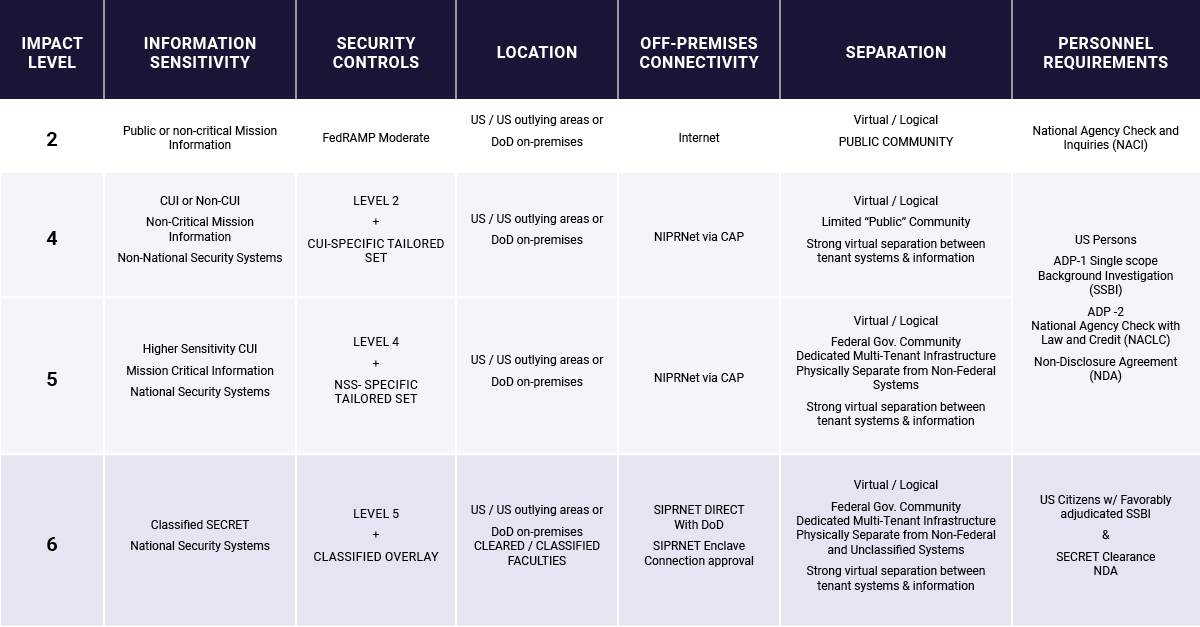
When using commercial cloud services, choice of cloud provider is important. Amazon Web Services (AWS) and Microsoft Azure are required to physically isolate the compute hardware they use for government customers from non-government customers, which leads to limited access to GPUs. However, notably, one DoD AI deployment specialist told us that GCP is his favorite cloud provider because it is much easier to access GPUs on government networks. Unlike other cloud providers, GCP is able to “mix” government and commercial compute hardware up to IL5 (Impact Level 5 on a security scale as outlined in the diagram below) which enables access to better compute infrastructure for some government workloads.
Choice of cloud provider may also be dictated by the kinds of AI models an application needs to use. Thus far, the DoD has largely relied on open source LLMs because they can be deployed locally on secure hardware.7 For example, one DoD AI deployment expert we interviewed described installing Mistral’s Mixtral LLM on a NVIDIA Jetson-equipped suitcase, allowing DoD users stationed abroad to use LLMs without access to cloud-hosted models. These choices will change as cloud providers continue to develop product offerings for hosting proprietary LLMs. Microsoft Azure, for instance, announced last month they are releasing GPT-4 on top secret networks pending accreditation later this year by government officials. Similarly, Anthropic is racing to get its Claude models deployed and distributed via AWS Bedrock and GCP, both with large federal customer bases.
Not all AI applications will be able to run in government cloud resources due to security and connectivity considerations. Many AI models will need to run on-prem and on-device. To run on edge and other compute-constrained devices, application developers will need to choose and optimize ML models carefully. When deploying language models, for instance, AI application developers could consider using small language models (SLMs) like Microsoft’s Phi-3, which use significantly less memory and computing power than larger models. To match LLM performance on specialized tasks, developers may need to fine-tune SLMs more, including on LLM outputs.
Developers will also need to optimize the ML models they hope to deploy using techniques like quantization and pruning. Optimization techniques typically compromise model performance for computational efficiency, so AI application developers will need to determine what tradeoffs they are willing to make between performance and efficiency. To ease the model optimization process, developers can use optimization tools like Apache TVM, EdgeImpulse, and tools developed for specific hardware like Qualcomm and NVIDIA’s AI optimization tools.
AI application developers may also consider selling hardware equipped with their software to circumvent some of these challenges.8 As Anduril’s Trae Stephens has noted, “it is significantly easier for the [Department of Defense] to buy metal than it is to buy software.” Both Anduril and Palantir sell hardware products that are optimized for their specific software (“wrapping” software in metal), using hardware “as a Trojan Horse to get software in the front door.”9
Other startups may choose to forge special partnerships with hardware providers to deploy their software. For instance, one startup we met has planned to partner with an AR headset hardware provider to deploy their data analytics software for the Pentagon. Model developers may also consider partnering with traditional defense primes who excel at building exquisite hardware for national security customers, but don’t necessarily have the talent to develop cutting edge AI algorithms for those hardware systems. For example, European AI startup Helsing has a strategic partnership with European defense prime Saab to deploy AI-enabled electronic warfare and surveillance capabilities on Saab’s fighter aircraft.
Finally, while the vast majority of the national security community’s on-prem and on-edge hardware is not designed for AI workloads, the DoD does have a high performance compute (HPC) cluster that AI model developers can use for government AI workloads. Until recently, developers had never used the DoD’s HPC cluster for AI workloads; rather, it was largely used to run complex simulation and physics-heavy workloads. The DoD’s HPC cluster has a number of GPUs available that have already been pre-authorized for unclassified and classified DoD use cases (HPC.mil can run NIPRNet, SIPRNet, and JWICS). See full list of HPC hardware available in unclassified networks here.
Classified Deployment
Those developing AI for national security will need to think hard about whether they want or need to deploy in classified networks. We’ve already laid out a myriad of challenges related to deploying AI in classified networks from limited access to real-time data to limited access to GPUs.
Most highly classified networks are “air gapped,” meaning they do not have access to the Internet. This lack of Internet access makes it difficult to load an application on a classified network. Those working on classified networks are not able to simply download any application they wish to run – each new piece of software needs to be approved to run on classified networks. In the past, application developers needed to physically deliver their software to classified networks via a CD or other storage hardware.
Luckily, today cloud providers have made it slightly easier to deploy to classified networks. For example, AWS GovCloud’s Diode service enables software providers to put data in an unclassified S3 bucket. The data from the low side S3 bucket is then transferred to a classified S3 bucket that can be accessed on classified networks (notably, there are still some challenges on actually getting the data in a format that makes it easy to transfer in this way).
Finally, when deploying to classified networks, model developers need to consider how they plan to monitor their applications’ performance. Once an application has shipped to a classified network, it is extremely difficult to update or monitor the application, so it is critical to make sure the application and model are running smoothly before high side deployment. Cleared engineers will be required to monitor model and application performance.
Deploying on classified networks can have significant benefits – it enables end users to use cutting edge AI technology to run critical classified workloads. Not deploying on classified networks can lead to serious headaches for end users – one startup we spoke to that was still in the midst of the ATO process highlighted some of the challenges their users face due to their lack of classified deployment. Many of their users need to constantly move in and out of a SCIF (sensitive compartmented information facility) while using their product, so that they can consult classified information. AI application developers will need to weigh the benefits and drawbacks of classified deployment and make the best deployment decision for their end users.
Conclusion
Developing and deploying AI for national security is a challenging yet critical endeavor. While AI technology (and demoware) races ahead, deployment and operational integration lags, posing a significant risk to maintaining U.S. dominance in an era of Great Power Competition. This landscape is outlined in strategies like the DoD AI and Data Strategy and the National Defense Strategy, which highlight the surge in potential AI applications yet emphasize the need for strategic deployment. This piece isn't meant as a recommendation but rather a roadmap of the hurdles newcomers might encounter when building AI for national security customers —hurdles that are pivotal to overcome if we want the best technology to win out for our warfighters and industrial base. We must think one step ahead, not just in terms of AI innovation, but more critically in its development and deployment, ensuring that the best minds are engaged in securing democracy and freedom.
As always, please reach out if you or anyone you know is building AI for national security, and please let us know your thoughts (or anything we missed) on developing and deploying AI for national security customers.

{kind=link}
Note: The opinions and views expressed in this article are solely our own and do not reflect the views, policies, or position of my employer or any other organization or individual with which we are affiliated.
For example, when the DoD first stood up Project Maven, the project was entirely focused on the fight against ISIS. As part of deploying Project Maven, the DoD built up organized, labeled data sets of drone and satellite imagery from the Middle East.
To be fair, the evaluation challenge is not unique to national security customers – even commercial entities are struggling to properly evaluate large language models.
USAF and USSF are using UDL for their Advanced Battle Management System (ABMS) and space situational awareness (SSA) programs. Both programs are part of the DoD’s overarching CJADC2 strategy, to integrate sensor data and provide warfighters with decision advantage.
Hardware constraints don’t only affect ML model performance – they can affect the performance of applications more broadly. Many of the laptops used to access classified networks are old and slow. One startup we spoke with mentioned that in addition to limiting the amount of compute needed to run their ML models, they were also working to simplify their web app UI broadly to ensure it runs efficiently on slow, old laptops.
To be fair, not all of the problems the DoD is trying to solve with ML require a GPU. For example, GPUs do not add much additional value when working with lower dimensional datasets (in some cases multi-threading through many CPUs is faster and easier than trying to transfer the problem to work on GPUs).
One piece of advice a DoD AI deployment expert offers to startups: build an open source version of your product. If a product is open source, DoD personnel can easily experiment with the product without any of the arduous processes (like the ATO process) outlined in this post. Then after the DoD has started using your free, open source product, the sales process for your paid product will be much quicker, as DoD end users are already familiar with the product and can serve as champions throughout the acquisitions process.
For example, those deploying AI-enabled applications that are particularly inference heavy may want to deploy their product on hardware equipped with specialized chips that are designed for inference like those developed by Groq or Google’s TPUs (in the case of edge inference - NVIDIA Jetson, providers like Armada, and even ASICs).
The DoD is working to improve their software acquisition methods. In January 2020 the DoD introduced a new software acquisition pathway to encourage iterative, agile product development.
 |
|